

A támadás előtti csend: a passzív OSINT reconnaissance szerepe a pentestekben
Egyetlen domain, néhány ügyes hacker és a passzív OSINT reconnaissance alkalmas arra, hogy támadók később kiberbiztonsági problémákat okozzanak. Tudni akarod, mennyi információt lehet felfedni cégedről pusztán a nyílt interneten elérhető adatok alapján és kíváncsi vagy, hogyan kerülheted el a bajt? Kezdjük az alapoktól!
OSINT: nyílt forrású információgyűjtés, strukturáltan
Az OSINT, vagyis az Open Source Intelligence olyan információgyűjtési módszertan, amely kizárólag nyilvánosan hozzáférhető forrásokra támaszkodik. Ide tartoznak többek között a domain-regisztrációs adatok, a DNS-információk, a tanúsítvány naplók, a keresőmotor-indexek, az archív weboldalak, valamint a közösségi és a szakmai platformokon elérhető adatok. Fontos hangsúlyozni, hogy az OSINT nem illegális adatgyűjtés, hanem a már eleve publikusan hozzáférhető adatok rendszerezett kihasználása.
Vagyis amikor informatikai biztonságról beszélünk, elsőként nem exploitokra, sebezhetőségekre és aktív támadásokra kell gondolnunk, hanem arra a csendes, mégis kritikus fázisra, amit úgy hívnak reconnaissance, vagyis a felderítés. Ez a legtöbb esetben teljesen legális.
Ugyanakkor a folyamat során a potenciális támadó rengeteg információt képes összegyűjteni anélkül, hogy bármilyen kapcsolatba lépne a vizsgált rendszerrel. Vagyis a támadó nem küld csomagot, nem szkennel portokat, nem próbál belépni, jogi szempontból tulajdonképpen nem is csinál semmit. Egyszerűen „csak” megnézi, mi lelhető fel a célpontról az interneten, illetve specifikus weboldalakon.
Miért kritikus a passzív reconnaissance?
A passzív reconnaissance során a vizsgált rendszerrel nincs közvetlen kapcsolat. Nem történik portszkennelés, nem érkeznek csomagok, nem indul aktív próbálkozás. A felderítés kizárólag harmadik felek által gyűjtött, nyilvános adatokra épül.
Fejlesztői szemmel ez különösen fontos: a célrendszer nem látja, hogy róla adatgyűjtés zajlik. Ennek ellenére gyakran meglepően részletes kép rajzolódik ki az infrastruktúráról, technológiai döntésekről és működési mintákról.
Egyszerű analógiával élve: nem belépünk egy házba, hanem az utcáról figyeljük meg. Ki mikor érkezik, milyen a napi rutin, milyen kapcsolatok látszanak kívülről. Ez önmagában még nem támadás – de komoly előkészítő fázis lehet.
Aktív vs. passzív felderítés
Az aktív reconnaissance során a célrendszerrel közvetlen kommunikáció történik. Portszkennelés, szolgáltatás-verziók lekérdezése, endpointok tesztelése – mind hatékony módszerek, de naplózhatók, és jogi, megfelelőségi kérdéseket is felvethetnek.
A passzív reconnaissance ezzel szemben olyan nyílt adatbázisokra, keresőmotorokra és archívumokra támaszkodik, amelyeket eredetileg üzleti, kutatási vagy biztonsági célból hoztak létre. Ezek nem támadási eszközök – mégis kiválóan alkalmasak arra, hogy egy szervezet digitális jelenlétét feltérképezzék.
Ez az a fázis, amely láthatatlan marad, mégis alapvetően meghatározza egy későbbi támadás vagy penetration test irányát.
A domain, mint kiindulópont
Egy vállalat külső támadási felületének legstabilabb belépési pontja a domain neve. A domainregisztrációs adatok önmagukban nem tartalmaznak sebezhetőséget, de kontextust adhatnak. Megmutatják, hogy az adott digitális identitás mióta létezik, milyen szolgáltatókon keresztül működik, és arra is rámutatnak, mennyire tudatosan van kezelve.
Egy régi, több évtizede regisztrált domain például szinte biztosan jelentős technológiai örökséget hordoz. Ilyen esetekben gyakoriak a régi alrendszerek, a migrált infrastruktúrák és az elfelejtett szolgáltatások is.
A domain státuszai arról mesélnek, mennyire védett a név egy esetleges átvétellel vagy manipulációval szemben, míg a névszerverek száma és típusa a DNS-architektúra összetettségéről ad képet. Mindez önmagában még persze nem jelent kockázatot, de jócskán ad alapot a további elemzéshez.
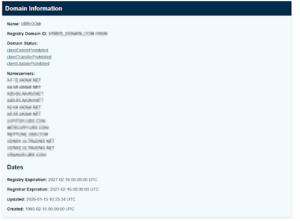
Domain regisztrációs információk és történeti adatok nyílt forrásból
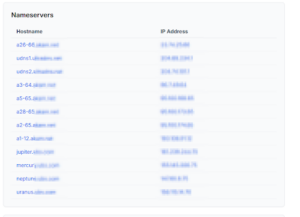
A domainhez tartozó névszerverek és azok publikus IP-címei
A DNS, a cache-ek és a passzív DNS adatbázisok szerepe
A DNS, vagyis a domain name system működése alapvetően publikus. Nem árt azonban tudni, hogy amikor egy domainhez IP-címet kérdezünk le, az eredmény nem csak egyszer jelenik meg. A válasz különböző resolverekben, szolgáltatóknál és biztonsági rendszerekben ideiglenesen vagy tartósan eltárolódik. Ezekből az adatokból jönnek létre az úgynevezett passzív DNS-adatbázisok.
Emlékeztetőül
- ezek a rendszerek nem aktív lekérdezéssel dolgoznak, hanem megfigyelik és archiválják a már megtörtént DNS-forgalmat.
- hatásukra visszamenőleg is láthatóvá válik, hogy egy domain milyen IP-címekhez tartozott korábban, milyen aldomainjei léteztek, vagy éppen milyen infrastruktúrán futott évekkel ezelőtt.
Publikusan elérhető DNS rekordok és IP-cím hozzárendelések
Biztonsági szempontból ez azért különösen értékes, mert a DNS történelmi adatai gyakran olyan rendszerekre mutatnak rá, amelyekről a szervezet már megfeledkezett, de valamilyen formában még elérhetők, vagy újrahasznosított infrastruktúrához kötődnek.
Tanúsítványok és Certificate Transparency
A modern internet egyik fontos biztonsági pillére a TLS, és ezzel együtt a Certificate Transparency rendszere. A szabályozás értelmében minden kiadott TLS-tanúsítványt nyilvános naplókban kell rögzíteni. Ezek a naplók bárki számára hozzáférhetők, és pontos képet adnak arról, hogy egy domainhez milyen tanúsítványokat állítottak ki az évek során.
Egy ilyen napló elemzése során nem csak az aktuális fő domain jelenik meg, hanem gyakran aldomainek tucatjai is, amelyek egy-egy tanúsítvány SAN-mezőjében szerepeltek. Ezek között rendszeresen előfordulnak fejlesztői, teszt vagy belső célra szánt hostnevek is.

Certificate Transparency naplókban megjelenő tanúsítványok és aldomain-ek
Mint az a fentiekben látható, az általunk vizsgált esetben annyi találat keletkezett, hogy az eredménylista nem fért ki egyetlen nézetbe. Ez önmagában is azt jelzi, hogy a domain mögött jelentős, összetett infrastruktúra áll.
Google-keresés mint passzív reconnaissance eszköz
A passzív reconnaissance egyik legerősebb, mégis gyakran alábecsült eszköze a Google kereső. Nem azért, mert „hackel”, hanem mert tükrözi azt, amit a weben – akár akaratlanul is – publikusan elérhetővé tettek. Ennek oka, hogy a keresőmotorok nem csak HTML-oldalakat indexelnek, hanem dokumentumokat, archívumokat, konfigurációkat és sok esetben olyan fájlokat is, amelyeknek soha nem lett volna szabad nyilvánosan elérhetővé válnia.
Az általunk modellezett esetben egy előre összeállított, általánosan használt keresési csomag került alkalmazásra, amely kifejezetten vállalati környezetben gyakran előforduló kitettségekre fókuszál.
Elsőként a publikus dokumentumokra irányuló keresések célja annak feltérképezése, hogy a domain alatt milyen irodai vagy strukturált fájlok érhetők el. Ezek tipikusan belső anyagok, exportált riportok vagy korábbi prezentációk lehetnek, amelyek metaadatokat és tartalmi információkat is hordozhatnak.
| site:www.xxx.com ext:doc | ext:docx | ext:odt | ext:rtf | ext:sxw | ext:psw | ext:ppt | ext:pptx | ext:pps | ext:csv |
Ezután az indexelt tartalomra irányuló keresés elsősorban azokra az esetekre világít rá, amikor egy webszerver könyvtárlistázást engedélyez, és a keresőmotor ezt indexelte.
| site:www.xxx.com intitle:index.of |
A konfigurációs állományok keresésekor azonban tipikusan olyan fájltípusokra történik a szűrés, amelyek alkalmazás- vagy rendszerbeállításokat tartalmazhatnak. Ezek önmagukban ritkán jelentenek azonnali sebezhetőséget, de technológiai és környezeti információkat árulhatnak el.
| site:www.xxx.com ext:xml | ext:conf | ext:cnf | ext:reg | ext:inf | ext:rdp | ext:cfg | ext:txt | ext:ora | ext:ini | ext:env |
Hasonló logika mentén történik az adatbázis- és mentésfájlok keresése is. Ezek a fájlok gyakran ideiglenesen kerülnek fel egy webszerverre, majd elfelejtődnek, miközben a keresőmotorok hosszú időre megőrzik nyomukat.
| site:www.xxx.com ext:sql | ext:dbf | ext:mdb
site:www.xxx.com ext:log site:www.xxx.com ext:bkf | ext:bkp | ext:bak | ext:old | ext:backup |
Ne feledjük, hogy a bejelentkezési és regisztrációs felületekre irányuló keresések célja nem a belépés, hanem annak feltérképezése, hogy hol helyezkednek el az autentikációs pontok, és milyen URL-minták jelennek meg a domain alatt.
| site:www.xxx.com inurl:login | inurl:signin | intitle:Login | intitle:”sign in” | inurl:auth
site:www.xxx.com inurl:signup | inurl:register | intitle:Signup |
A hibaüzenetek keresése is különösen fontos, mert gyakran technológiai részleteket, adatbázis-típusokat vagy backend-logikát fednek fel anélkül, hogy bármit aktívan tesztelnének.
| site:www.xxx.com intext:”sql syntax near” | intext:”syntax error has occurred” | intext:”incorrect syntax near” | intext:”unexpected end of SQL command” | intext:”Warning: mysql_connect()” | intext:”Warning: mysql_query()” | intext:”Warning: pg_connect()”
site:www.xxx.com „PHP Parse error” | „PHP Warning” | „PHP Error” |
A kódrészletek és konfigurációk szivárgásának vizsgálata kiterjed harmadik fél platformokra is. Paste oldalak, kódtárak és fórumok gyakran tartalmaznak példákat, hibajegyeket vagy ideiglenes megoldásokat, amelyekben domainnevek, API-végpontok vagy belső részletek jelennek meg.
| site:pastebin.com | site:paste2.org | site:pastehtml.com | site:slexy.org | site:snipplr.com | site:snipt.net | site:textsnip.com | site:bitpaste.app | site:justpaste.it | site:heypasteit.com | site:hastebin.com | site:dpaste.org | site:dpaste.com | site:codepad.org | site:jsitor.com | site:codepen.io | site:jsfiddle.net | site:dotnetfiddle.net | site:phpfiddle.org | site:ide.geeksforgeeks.org | site:repl.it | site:ideone.com | site:paste.debian.net | site:paste.org | site:paste.org.ru | site:codebeautify.org | site:codeshare.io | site:trello.com www.xxx.com
site:github.com | site:gitlab.com „www.xxx.com” site:stackoverflow.com „www.xxx.com” |
Végül a subdomain és sub-subdomain keresések lehetővé teszik, hogy a keresőmotor által már ismert hostnevek is feltérképezésre kerüljenek.
| site:*.www.xxx.com
site:*.*.www.xxx.com |
Ezek a keresések nem garantálják, hogy találat lesz, de azt megmutatják, mit lát a világ a vizsgált vállalkozásról.
Dokumentumok és további elemzési lehetőségek
Fontos hangsúlyozni, hogy ebben a konkrét esetben nem történt metaadat-elemzés és nem állítjuk, hogy érzékeny információk kerültek volna elő dokumentumokból. Ugyanakkor szakmai szempontból releváns megemlíteni, hogy az ilyen módon megtalált fájlok később tovább elemezhetők, például metaadat-vizsgálattal vagy névkonvenciók feltérképezésével. Ezek a lépések már egy következő fázist jelentenének, és jól mutatják, hogyan épül egymásra a reconnaissance folyamata.
Emberi tényezők az OSINT-ben
A passzív reconnaissance nem áll meg a technikai infrastruktúránál, hiszen amikor már látható, hogy egy szervezet milyen méretű, milyen földrajzi jelenléttel és milyen technológiai háttérrel rendelkezik, az emberi oldal feltérképezése a szükségszerű következő lépés.
Nem feltétlenül kell nagy dolgokra gondolni, hiszen a LinkedIn és más szakmai közösségi platformok lehetővé teszik, hogy egyszerűen kiderítsük, kik és milyen szerepkörökben, milyen szervezeti struktúra mentén dolgoznak az adott munkáltatónál. zek az információk nyilvánosak és csak önmagukban ártalmatlanok. Technikai kontextusba helyezve aazonban egy már célzott támadási forgatókönyvek alapját képezhetik.
Nyilvános szakmai közösségi adatok mint a későbbi célzott támadások alapjai
Ez a pont az, ahol a passzív reconnaissance eredményei később phishing, social engineering vagy hitelesítőadat-keresések irányába is továbbvihetők, például nyilvános adatbázisok vagy breach-kereső szolgáltatások segítségével.
Shodan: amikor mások már elvégezték a szkennelést
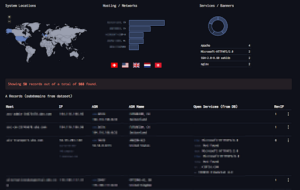
A Shodan egy olyan keresőmotor, amely az internetre kötött eszközök által visszaadott bannerinformációkat gyűjti össze. Fontos hangsúlyozni, hogy amikor egy elemző Shodant használ, nem ő szkenneli a célrendszert. Egyszerűen megnézi, mit gyűjtöttek össze mások korábban.
Egy domain vagy szervezet nevére keresve kirajzolódik, milyen IP-címekhez köthető, milyen szolgáltatások voltak elérhetők, és mely portok voltak nyitva az adott időpontban.
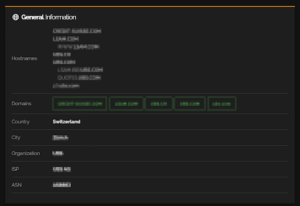
Publikus IP-címhez tartozó hálózati és földrajzi információk Shodan alapján
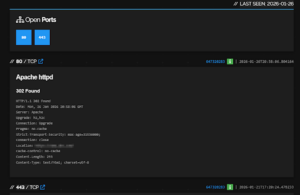
Shodan által gyűjtött publikus szolgáltatás- és portinformációk
Ezek az adatok további elemzésre adnak lehetőséget, például földrajzi elhelyezkedés, hosting szolgáltató vagy hálózati struktúra szintjén.
Internet Archive és a Wayback Machine
Az Internet Archive több évtizede archiválja a weboldalak tartalmát. Egy domain esetében akár több tízezer mentés is rendelkezésre állhat, egészen az 1990-es évek közepéig visszamenően.
Weboldal mentései az Internet Archive Wayback Machine-ben
Ezek a mentések lehetővé teszik annak vizsgálatát, hogy a weboldal hogyan változott az idő során. Előfordulhat, hogy régi adminfelületek, félkész funkciók vagy már eltávolított tartalmak még mindig visszanézhetők. Ezekből következtetni lehet belső működésre, technológiai döntésekre, vagy akár adatkezelési gyakorlatokra.
Összegzés
A bemutatott lépések jól szemléltetik, hogy milyen mélységű képet lehet alkotni egy szervezetről kizárólag passzív módszerekkel. Domain-adatok, DNS-történet, tanúsítványok, keresőmotor-indexek, archívumok és nyilvános platformok együtt olyan információhalmazt alkotnak, amelyből egy tapasztalt támadó nagyon pontos következtetéseket tud levonni.
És mivel mindez úgy történik, hogy a célrendszer egyetlen pillanatig sem érzékeli a felderítést, a passzív reconnaissance nemcsak támadói technika, hanem védelmi szempontból is kulcsfontosságú ellenőrzési pont.
Alkalmazott források a reconnaissance bemutatására és módszertani megjegyzések
A cikkben bemutatott passzív reconnaissance lépések kizárólag nyílt forrású, bárki számára hozzáférhető adatbázisokra és archívumokra támaszkodtak.
A domain-regisztrációs adatok értelmezéséhez az ICANN hivatalos lekérdező felülete, valamint a who.is szolgáltatás került felhasználásra. A hálózati és autonóm rendszer szintű összefüggések vizsgálatához a BGP- és ASN-adatok nyilvános gyűjtőoldalai nyújtottak kontextust.
Az infrastruktúra látható felületének feltérképezéséhez a Shodan által korábban gyűjtött adatok szolgáltak alapul, míg az emberi tényezők és szervezeti struktúrák megértéséhez a LinkedIn nyilvánosan elérhető információi adtak támpontot.
A weboldal történeti elemzéséhez az Internet Archive Wayback Machine biztosította a szükséges időbeli visszatekintést, amely ebben az esetben több mint másfél évtizednyi mentést tett elérhetővé.
A DNS-hez kapcsolódó történeti és megfigyelési adatok elemzéséhez passzív DNS-adatbázisok kerültek alkalmazásra, amelyek lehetővé tették a korábbi IP-hozzárendelések és infrastruktúra-változások megismerését. A tanúsítvány-alapú feltérképezés során a Certificate Transparency naplók nyújtottak betekintést az évek során kiállított TLS-tanúsítványokba és az azokban szereplő aldomain-kbe.
Fontos hangsúlyozni, hogy a bemutatott eszközök és szolgáltatások nem kizárólagosak. Az OSINT világa rendkívül széles, és az alkalmazható források köre folyamatosan bővül. Általános iránymutatásként és kiindulópontként az osintframework.com kiváló összefoglalást ad az elérhető technikákról és adatforrásokról, legyen szó technikai, személyi vagy infrastruktúra-központú felderítésről. Ez a keretrendszer jól szemlélteti, hogy a nyílt forrású információgyűjtés mennyire strukturált és sokrétű terület.
Ez a cikk nem a teljesség igényével készült, hanem azt kívánta bemutatni, hogy egyetlen domaint kiindulópontként alkalmazva mennyi releváns információ gyűjthető össze teljesen passzív módon. A bemutatott módszerek egyaránt alkalmazhatók védelmi ellenőrzések, biztonságtudatossági programok és professzionális penetration testek előkészítése során.
Ha vállalata összetett digitális infrastruktúrát üzemeltet, érdemes tisztában lennie azzal, mit árul el magáról a cég a nyílt interneten! A professzionális, védelmi célú OSINT-alapú felderítés segít feltárni azokat a kitettségeket, amelyek akár egy támadás előkészítését szolgálhatják. Vegye fel velünk a kapcsolatot, ha szeretné felmérni a szervezetére leselkedő valós veszély mértékét!

